
In the previous articles: Database Cluster using Patroni: Prerequisites (section 1) we has setup node and ready to build cluster.
Now In this section we will build Database Cluster using patroni
Please make sure you was setup your node by following previous section
Clone Template
will will use Vitabaks Repository (postgresql_cluster) as our template
# clone using git
git clone https://github.com/vitabaks/postgresql_cluster
# go to
cd /postgresql_clusterConfig Inventory
Edit file /postgresql_cluster/automation/inventory
# if dcs_exists: false and dcs_type: "etcd"
[etcd_cluster] # recommendation: 3, or 5-7 nodes
192.168.0.12
192.168.0.13
192.168.0.14
# if with_haproxy_load_balancing: true
[balancers]
192.168.0.11
# PostgreSQL nodes
[master]
192.168.0.12 hostname=stg-psql-node1
[replica]
192.168.0.13 hostname=stg-psql-node2
192.168.0.14 hostname=stg-psql-node3
[postgres_cluster:children]
master
replica
# Connection settings
[all:vars]
ansible_connection='ssh'
ansible_ssh_port='22'
ansible_user='root'
ansible_ssh_pass='yourPassword'Config Variables as you need
Edit file Edit file /postgresql_cluster/automation/vars/main.yml.
Please note: config depends on your needs and may vary from others.
---
# ---------------------------------------------------------------------
# Proxy variables (optional) for download packages using a proxy server
proxy_env: {} # yamllint disable rule:braces
# http_proxy: http://10.128.64.9:3128
# https_proxy: http://10.128.64.9:3128
# ---------------------------------------------------------------------
# Cluster variables
cluster_vip: "" # IP address for client access to the databases in the cluster (optional).
vip_interface: "{{ ansible_default_ipv4.interface }}" # interface name (e.g., "ens32").
# Note: VIP-based solutions such as keepalived or vip-manager may not function correctly in cloud environments.
patroni_cluster_name: "cluster-name" # the cluster name (must be unique for each cluster)
patroni_superuser_username: "postgres"
patroni_superuser_password: "yourdatasePassword" # Please specify a password. If not defined, will be generated automatically during deployment.
patroni_replication_username: "replicator"
patroni_replication_password: "replicator" # Please specify a password. If not defined, will be generated automatically during deployment.
synchronous_mode: false # or 'true' for enable synchronous database replication
synchronous_mode_strict: false # if 'true' then block all client writes to the master, when a synchronous replica is not available
synchronous_node_count: 1 # number of synchronous standby databases
# Load Balancing
with_haproxy_load_balancing: true # or 'true' if you want to install and configure the load-balancing
haproxy_listen_port:
master: 5000
replicas: 5001
replicas_sync: 5002
replicas_async: 5003
# The following ('_direct') ports are used for direct connections to the PostgreSQL database,
# bypassing the PgBouncer connection pool (if 'pgbouncer_install' is 'true').
# Uncomment the relevant lines if you need to set up direct connections.
# master_direct: 6000
# replicas_direct: 6001
# replicas_sync_direct: 6002
# replicas_async_direct: 6003
stats: 7000
haproxy_maxconn:
global: 100000
master: 10000
replica: 10000
haproxy_timeout:
client: "60m"
server: "60m"
# Optionally declare log format for haproxy.
# Uncomment following lines (and remove extra space in front of variable definition) for JSON structured log format.
# haproxy_log_format: "{
# \"pid\":%pid,\
# \"haproxy_frontend_type\":\"tcp\",\
# \"haproxy_process_concurrent_connections\":%ac,\
# \"haproxy_frontend_concurrent_connections\":%fc,\
# \"haproxy_backend_concurrent_connections\":%bc,\
# \"haproxy_server_concurrent_connections\":%sc,\
# \"haproxy_backend_queue\":%bq,\
# \"haproxy_server_queue\":%sq,\
# \"haproxy_queue_wait_time\":%Tw,\
# \"haproxy_server_wait_time\":%Tc,\
# \"response_time\":%Td,\
# \"session_duration\":%Tt,\
# \"request_termination_state\":\"%tsc\",\
# \"haproxy_server_connection_retries\":%rc,\
# \"remote_addr\":\"%ci\",\
# \"remote_port\":%cp,\
# \"frontend_addr\":\"%fi\",\
# \"frontend_port\":%fp,\
# \"frontend_ssl_version\":\"%sslv\",\
# \"frontend_ssl_ciphers\":\"%sslc\",\
# \"haproxy_frontend_name\":\"%f\",\
# \"haproxy_backend_name\":\"%b\",\
# \"haproxy_server_name\":\"%s\",\
# \"response_size\":%B,\
# \"request_size\":%U\
# }"
# keepalived (if 'cluster_vip' is specified and 'with_haproxy_load_balancing' is 'true')
keepalived_virtual_router_id: "{{ cluster_vip.split('.')[3] | int }}" # The last octet of 'cluster_vip' IP address is used by default.
# virtual_router_id - must be unique in the network (available values are 0..255).
# vip-manager (if 'cluster_vip' is specified and 'with_haproxy_load_balancing' is 'false')
vip_manager_version: "2.6.0" # version to install
vip_manager_conf: "/etc/patroni/vip-manager.yml"
vip_manager_interval: "1000" # time (in milliseconds) after which vip-manager wakes up and checks if it needs to register or release ip addresses.
vip_manager_iface: "{{ vip_interface }}" # interface to which the virtual ip will be added
vip_manager_ip: "{{ cluster_vip }}" # the virtual ip address to manage
vip_manager_mask: "24" # netmask for the virtual ip
# DCS (Distributed Consensus Store)
dcs_exists: false # or 'true' if you don't want to deploy a new etcd cluster
dcs_type: "etcd" # or 'consul'
# if dcs_type: "etcd" and dcs_exists: false
etcd_version: "3.5.15" # version for deploy etcd cluster
etcd_data_dir: "/var/lib/etcd"
etcd_cluster_name: "etcd-{{ patroni_cluster_name }}" # ETCD_INITIAL_CLUSTER_TOKEN
# if dcs_type: "etcd" and dcs_exists: true
patroni_etcd_hosts: [] # list of servers of an existing etcd cluster
# - { host: "10.128.64.140", port: "2379" }
# - { host: "10.128.64.142", port: "2379" }
# - { host: "10.128.64.143", port: "2379" }
patroni_etcd_namespace: "service" # (optional) etcd namespace (prefix)
patroni_etcd_username: "" # (optional) username for etcd authentication
patroni_etcd_password: "" # (optional) password for etcd authentication
patroni_etcd_protocol: "" # (optional) http or https, if not specified http is used
# more options you can specify in the roles/patroni/templates/patroni.yml.j2
# https://patroni.readthedocs.io/en/latest/yaml_configuration.html#etcd
# https://patroni.readthedocs.io/en/latest/yaml_configuration.html#consul
# if dcs_type: "consul"
consul_version: "latest" # or a specific version (e.q., '1.18.2') if 'consul_install_from_repo' is 'false'
consul_install_from_repo: true # specify 'false' only if patroni_installation_method: "pip" is used
consul_config_path: "/etc/consul"
consul_configd_path: "{{ consul_config_path }}/conf.d"
consul_data_path: "/var/lib/consul"
consul_domain: "consul" # Consul domain name
consul_datacenter: "dc1" # Datacenter label (can be specified for each host in the inventory)
consul_disable_update_check: true # Disables automatic checking for security bulletins and new version releases
consul_enable_script_checks: true # This controls whether health checks that execute scripts are enabled on this agent
consul_enable_local_script_checks: true # Enable them when they are defined in the local configuration files
consul_ui: false # Enable the consul UI?
consul_syslog_enable: true # Enable logging to syslog
consul_iface: "{{ ansible_default_ipv4.interface }}" # specify the interface name with a Private IP (ex. "enp7s0")
# TLS
# You can enable TLS encryption by dropping a CA certificate, server certificate, and server key in roles/consul/files/
consul_tls_enable: false
consul_tls_ca_crt: "ca.crt"
consul_tls_server_crt: "server.crt"
consul_tls_server_key: "server.key"
# DNS
consul_recursors: [] # List of upstream DNS servers
consul_dnsmasq_enable: true # Enable DNS forwarding with Dnsmasq
consul_dnsmasq_cache: 0 # dnsmasq cache-size (0 - disable caching)
consul_dnsmasq_servers: "{{ nameservers }}" # Upstream DNS servers used by dnsmasq
consul_join: [] # List of LAN servers of an existing consul cluster, to join.
# - "10.128.64.140"
# - "10.128.64.142"
# - "10.128.64.143"
# https://developer.hashicorp.com/consul/docs/discovery/services
consul_services:
- name: "{{ patroni_cluster_name }}"
id: "{{ patroni_cluster_name }}-master"
tags: ['master', 'primary']
port: "{{ pgbouncer_listen_port }}" # or "{{ postgresql_port }}" if pgbouncer_install: false
checks:
- { http: "http://{{ inventory_hostname }}:{{ patroni_restapi_port }}/primary", interval: "2s" }
- { args: ["systemctl", "status", "pgbouncer"], interval: "5s" } # comment out this check if pgbouncer_install: false
- name: "{{ patroni_cluster_name }}"
id: "{{ patroni_cluster_name }}-replica"
tags: ['replica']
port: "{{ pgbouncer_listen_port }}"
checks:
- { http: "http://{{ inventory_hostname }}:{{ patroni_restapi_port }}/replica?lag={{ patroni_maximum_lag_on_replica }}", interval: "2s" }
- { args: ["systemctl", "status", "pgbouncer"], interval: "5s" }
# - name: "{{ patroni_cluster_name }}"
# id: "{{ patroni_cluster_name }}-sync-replica"
# tags: ['sync-replica']
# port: "{{ pgbouncer_listen_port }}"
# checks:
# - { http: "http://{{ inventory_hostname }}:{{ patroni_restapi_port }}/sync", interval: "2s" }
# - { args: ["systemctl", "status", "pgbouncer"], interval: "5s" }
# - name: "{{ patroni_cluster_name }}"
# id: "{{ patroni_cluster_name }}-async-replica"
# tags: ['async-replica']
# port: "{{ pgbouncer_listen_port }}"
# checks:
# - { http: "http://{{ inventory_hostname }}:{{ patroni_restapi_port }}/async?lag={{ patroni_maximum_lag_on_replica }}", interval: "2s" }
# - { args: ["systemctl", "status", "pgbouncer"], interval: "5s" }
# PostgreSQL variables
postgresql_version: 16
# postgresql_data_dir: see vars/Debian.yml or vars/RedHat.yml
postgresql_listen_addr: "0.0.0.0" # Listen on all interfaces. Or use "{{ inventory_hostname }},127.0.0.1" to listen on a specific IP address.
postgresql_port: 5432
postgresql_encoding: "UTF8" # for bootstrap only (initdb)
postgresql_locale: "en_US.UTF-8" # for bootstrap only (initdb)
postgresql_data_checksums: true # for bootstrap only (initdb)
postgresql_password_encryption_algorithm: "scram-sha-256" # or "md5" if your clients do not work with passwords encrypted with SCRAM-SHA-256
# (optional) list of users to be created (if not already exists)
postgresql_users: []
# - { name: "monitoring_auth_username", password: "monitoring_user_password", flags: "LOGIN", role: "pg_monitor" } # monitoring Service Account
# - { name: "mydb-user", password: "mydb-user-pass", flags: "SUPERUSER" }
# - { name: "", password: "", flags: "NOSUPERUSER" }
# - { name: "", password: "", flags: "NOSUPERUSER" }
# - { name: "", password: "", flags: "NOLOGIN" }
# (optional) list of databases to be created (if not already exists)
postgresql_databases: []
# - { db: "mydatabase", encoding: "UTF8", lc_collate: "ru_RU.UTF-8", lc_ctype: "ru_RU.UTF-8", owner: "mydb-user" }
# - { db: "mydatabase2", encoding: "UTF8", lc_collate: "ru_RU.UTF-8", lc_ctype: "ru_RU.UTF-8", owner: "mydb-user", conn_limit: "50" }
# - { db: "", encoding: "UTF8", lc_collate: "en_US.UTF-8", lc_ctype: "en_US.UTF-8", owner: "" }
# - { db: "", encoding: "UTF8", lc_collate: "en_US.UTF-8", lc_ctype: "en_US.UTF-8", owner: "" }
# (optional) list of schemas to be created (if not already exists)
postgresql_schemas: []
# - { schema: "myschema", db: "mydatabase", owner: "mydb-user" }
# (optional) list of privileges to be granted (if not already exists) or revoked
# https://docs.ansible.com/ansible/latest/collections/community/postgresql/postgresql_privs_module.html#examples
# The db (which is the database to connect to) and role parameters are required
postgresql_privs: []
# - { role: "test", privs: "SELECT,INSERT,UPDATE", type: "table", db: "test2", objs: "test" } # grant SELECT, INSERT, UPDATE on a table to role test
# - { role: "test-user", privs: "ALL", type: "database", db: "test-db", objs: "test-db" } # grant ALL on a database to role test-user
# - { role: "mydb-user", privs: "SELECT", type: "table", db: "mydb", objs: "my_table", schema: "my_schema" } # grant SELECT on a table and schema
# - { role: "user", privs: "EXECUTE", type: "function", db: "db1", objs: "pg_ls_waldir()", schema: "pg_catalog" } # grant EXECUTE on a function
# - { role: "user, privs: "SELECT", type: "table", db: "mydb", objs: "table2", schema: "schema2", state: "absent" } # revoke SELECT on a table2 and schema2
# - { role: "test, test2", privs: "CREATE", type: "database", db: "test2", objs: "test2" } # grant CREATE on a database test2 to role test and test2
# (optional) list of database extensions to be created (if not already exists)
postgresql_extensions:
- { ext: "pg_stat_statements", db: "postgres" }
# - { ext: "pg_stat_statements", db: "postgres" }
# - { ext: "pg_stat_statements", db: "mydatabase" }
# - { ext: "pg_stat_statements", db: "mydatabase", schema: "myschema" }
# - { ext: "pg_stat_statements", db: "" }
# - { ext: "pg_stat_statements", db: "" }
# - { ext: "pg_repack", db: "" } # postgresql-<version>-repack package is required
# - { ext: "pg_stat_kcache", db: "" } # postgresql-<version>-pg-stat-kcache package is required
# - { ext: "", db: "" }
# - { ext: "", db: "" }
# postgresql parameters to bootstrap dcs (are parameters for example)
postgresql_parameters:
- { option: "max_connections", value: "1000" }
- { option: "superuser_reserved_connections", value: "5" }
- { option: "password_encryption", value: "{{ postgresql_password_encryption_algorithm }}" }
- { option: "max_locks_per_transaction", value: "512" }
- { option: "max_prepared_transactions", value: "0" }
- { option: "huge_pages", value: "try" } # "vm.nr_hugepages" is auto-configured for shared_buffers >= 8GB (if huge_pages_auto_conf is true)
- { option: "shared_buffers", value: "{{ (ansible_memtotal_mb * 0.25) | int }}MB" } # by default, 25% of RAM
- { option: "effective_cache_size", value: "{{ (ansible_memtotal_mb * 0.75) | int }}MB" } # by default, 75% of RAM
- { option: "work_mem", value: "128MB" } # please change this value
- { option: "maintenance_work_mem", value: "256MB" } # please change this value
- { option: "checkpoint_timeout", value: "15min" }
- { option: "checkpoint_completion_target", value: "0.9" }
- { option: "min_wal_size", value: "2GB" }
- { option: "max_wal_size", value: "8GB" } # or 16GB/32GB
- { option: "wal_buffers", value: "32MB" }
- { option: "default_statistics_target", value: "1000" }
- { option: "seq_page_cost", value: "1" }
- { option: "random_page_cost", value: "1.1" } # or "4" for HDDs with slower random access
- { option: "effective_io_concurrency", value: "200" } # or "2" for traditional HDDs with lower I/O parallelism
- { option: "synchronous_commit", value: "on" } # or 'off' if you can you lose single transactions in case of a crash
- { option: "autovacuum", value: "on" } # never turn off the autovacuum!
- { option: "autovacuum_max_workers", value: "5" }
- { option: "autovacuum_vacuum_scale_factor", value: "0.01" } # or 0.005/0.001
- { option: "autovacuum_analyze_scale_factor", value: "0.01" }
- { option: "autovacuum_vacuum_cost_limit", value: "500" } # or 1000/5000
- { option: "autovacuum_vacuum_cost_delay", value: "2" }
- { option: "autovacuum_naptime", value: "1s" }
- { option: "max_files_per_process", value: "4096" }
- { option: "archive_mode", value: "on" }
- { option: "archive_timeout", value: "1800s" }
- { option: "archive_command", value: "cd ." } # not doing anything yet with WAL-s
# - { option: "archive_command", value: "{{ wal_g_archive_command }}" } # archive WAL-s using WAL-G
# - { option: "archive_command", value: "{{ pgbackrest_archive_command }}" } # archive WAL-s using pgbackrest
- { option: "wal_level", value: "logical" }
- { option: "wal_keep_size", value: "2GB" }
- { option: "max_wal_senders", value: "10" }
- { option: "max_replication_slots", value: "10" }
- { option: "hot_standby", value: "on" }
- { option: "wal_log_hints", value: "on" }
- { option: "wal_compression", value: "on" }
- { option: "shared_preload_libraries", value: "pg_stat_statements,auto_explain" }
- { option: "pg_stat_statements.max", value: "10000" }
- { option: "pg_stat_statements.track", value: "all" }
- { option: "pg_stat_statements.track_utility", value: "false" }
- { option: "pg_stat_statements.save", value: "true" }
- { option: "auto_explain.log_min_duration", value: "10s" } # enable auto_explain for 10-second logging threshold. Decrease this value if necessary
- { option: "auto_explain.log_analyze", value: "true" }
- { option: "auto_explain.log_buffers", value: "true" }
- { option: "auto_explain.log_timing", value: "false" }
- { option: "auto_explain.log_triggers", value: "true" }
- { option: "auto_explain.log_verbose", value: "true" }
- { option: "auto_explain.log_nested_statements", value: "true" }
- { option: "auto_explain.sample_rate", value: "0.01" } # enable auto_explain for 1% of queries logging threshold
- { option: "track_io_timing", value: "on" }
- { option: "log_lock_waits", value: "on" }
- { option: "log_temp_files", value: "0" }
- { option: "track_activities", value: "on" }
- { option: "track_activity_query_size", value: "4096" }
- { option: "track_counts", value: "on" }
- { option: "track_functions", value: "all" }
- { option: "log_checkpoints", value: "on" }
- { option: "logging_collector", value: "on" }
- { option: "log_truncate_on_rotation", value: "on" }
- { option: "log_rotation_age", value: "1d" }
- { option: "log_rotation_size", value: "0" }
- { option: "log_line_prefix", value: "%t [%p-%l] %r %q%u@%d " }
- { option: "log_filename", value: "postgresql-%a.log" }
- { option: "log_directory", value: "{{ postgresql_log_dir }}" }
- { option: "hot_standby_feedback", value: "on" } # allows feedback from a hot standby to the primary that will avoid query conflicts
- { option: "max_standby_streaming_delay", value: "30s" }
- { option: "wal_receiver_status_interval", value: "10s" }
- { option: "idle_in_transaction_session_timeout", value: "10min" } # reduce this timeout if possible
- { option: "jit", value: "off" }
- { option: "max_worker_processes", value: "24" }
- { option: "max_parallel_workers", value: "8" }
- { option: "max_parallel_workers_per_gather", value: "2" }
- { option: "max_parallel_maintenance_workers", value: "2" }
- { option: "tcp_keepalives_count", value: "10" }
- { option: "tcp_keepalives_idle", value: "300" }
- { option: "tcp_keepalives_interval", value: "30" }
# - { option: "old_snapshot_threshold", value: "60min" }
# - { option: "", value: "" }
# - { option: "", value: "" }
# Set this variable to 'true' if you want the cluster to be automatically restarted
# after changing the 'postgresql_parameters' variable that requires a restart in the 'config_pgcluster.yml' playbook.
# By default, the cluster will not be automatically restarted.
pending_restart: false
# specify additional hosts that will be added to the pg_hba.conf
postgresql_pg_hba:
- { type: "local", database: "all", user: "{{ patroni_superuser_username }}", address: "", method: "trust" }
- { type: "local", database: "all", user: "{{ pgbouncer_auth_username }}", address: "", method: "trust" } # required for pgbouncer auth_user
- { type: "local", database: "replication", user: "{{ patroni_superuser_username }}", address: "", method: "trust" }
- { type: "local", database: "all", user: "all", address: "", method: "{{ postgresql_password_encryption_algorithm }}" }
- { type: "host", database: "all", user: "all", address: "127.0.0.1/32", method: "{{ postgresql_password_encryption_algorithm }}" }
- { type: "host", database: "all", user: "all", address: "::1/128", method: "{{ postgresql_password_encryption_algorithm }}" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "{{ postgresql_password_encryption_algorithm }}" }
# - { type: "host", database: "mydatabase", user: "mydb-user", address: "192.168.0.0/24", method: "{{ postgresql_password_encryption_algorithm }}" }
# - { type: "host", database: "all", user: "all", address: "192.168.0.0/24", method: "ident", options: "map=main" } # use pg_ident
# list of lines that Patroni will use to generate pg_ident.conf
postgresql_pg_ident: []
# - { mapname: "main", system_username: "postgres", pg_username: "backup" }
# - { mapname: "", system_username: "", pg_username: "" }
# the password file (~/.pgpass)
postgresql_pgpass:
- "localhost:{{ postgresql_port }}:*:{{ patroni_superuser_username }}:{{ patroni_superuser_password }}"
- "{{ inventory_hostname }}:{{ postgresql_port }}:*:{{ patroni_superuser_username }}:{{ patroni_superuser_password }}"
- "*:{{ pgbouncer_listen_port }}:*:{{ patroni_superuser_username }}:{{ patroni_superuser_password }}"
# - hostname:port:database:username:password
# PgBouncer parameters
pgbouncer_install: true # or 'false' if you do not want to install and configure the pgbouncer service
pgbouncer_processes: 1 # Number of pgbouncer processes to be used. Multiple processes use the so_reuseport option for better performance.
pgbouncer_conf_dir: "/etc/pgbouncer"
pgbouncer_log_dir: "/var/log/pgbouncer"
pgbouncer_listen_addr: "0.0.0.0" # Listen on all interfaces. Or use "{{ inventory_hostname }}" to listen on a specific IP address.
pgbouncer_listen_port: 6432
pgbouncer_max_client_conn: 100000
pgbouncer_max_db_connections: 10000
pgbouncer_max_prepared_statements: 1024
pgbouncer_query_wait_timeout: 120
pgbouncer_default_pool_size: 100
pgbouncer_default_pool_mode: "session"
pgbouncer_admin_users: "{{ patroni_superuser_username }}" # comma-separated list of users, who are allowed to change settings
pgbouncer_stats_users: "{{ patroni_superuser_username }}" # comma-separated list of users who are just allowed to use SHOW command
pgbouncer_ignore_startup_parameters: "extra_float_digits,geqo,search_path"
pgbouncer_auth_type: "{{ postgresql_password_encryption_algorithm }}"
pgbouncer_auth_user: true # or 'false' if you want to manage the list of users for authentication in the database via userlist.txt
pgbouncer_auth_username: pgbouncer # user who can query the database via the user_search function
pgbouncer_auth_password: "pgbouncerZ3c#r3Pasword" # If not defined, a password will be generated automatically during deployment
pgbouncer_auth_dbname: "postgres"
pgbouncer_client_tls_sslmode: "disable"
pgbouncer_client_tls_key_file: ""
pgbouncer_client_tls_cert_file: ""
pgbouncer_client_tls_ca_file: ""
pgbouncer_client_tls_protocols: "secure" # allowed values: tlsv1.0, tlsv1.1, tlsv1.2, tlsv1.3, all, secure (tlsv1.2,tlsv1.3)
pgbouncer_client_tls_ciphers: "default" # allowed values: default, secure, fast, normal, all (not recommended)
pgbouncer_pools:
- { name: "postgres", dbname: "postgres", pool_parameters: "" }
# - { name: "mydatabase", dbname: "mydatabase", pool_parameters: "pool_size=20 pool_mode=transaction" }
# - { name: "", dbname: "", pool_parameters: "" }
# - { name: "", dbname: "", pool_parameters: "" }
# Extended variables (optional)
patroni_restapi_listen_addr: "0.0.0.0" # Listen on all interfaces. Or use "{{ inventory_hostname }}" to listen on a specific IP address.
patroni_restapi_port: 8008
patroni_restapi_username: "patroni"
patroni_restapi_password: "" # If not defined, a password will be generated automatically during deployment.
patroni_ttl: 30
patroni_loop_wait: 10
patroni_retry_timeout: 10
patroni_master_start_timeout: 300
patroni_maximum_lag_on_failover: 1048576 # (1MB) the maximum bytes a follower may lag to be able to participate in leader election.
patroni_maximum_lag_on_replica: "100MB" # the maximum of lag that replica can be in order to be available for read-only queries.
# https://patroni.readthedocs.io/en/latest/yaml_configuration.html#postgresql
patroni_callbacks: []
# - {action: "on_role_change", script: ""}
# - {action: "on_stop", script: ""}
# - {action: "on_restart", script: ""}
# - {action: "on_reload", script: ""}
# - {action: "on_role_change", script: ""}
# https://patroni.readthedocs.io/en/latest/replica_bootstrap.html#standby-cluster
# Requirements:
# 1. the cluster name for Standby Cluster must be unique ('patroni_cluster_name' variable)
# 2. the IP addresses (or network) of the Standby Cluster servers must be added to the pg_hba.conf of the Main Cluster ('postgresql_pg_hba' variable).
patroni_standby_cluster:
host: "" # an address of remote master
port: "5432" # a port of remote master
# primary_slot_name: "" # which slot on the remote master to use for replication (optional)
# restore_command: "" # command to restore WAL records from the remote master to standby leader (optional)
# recovery_min_apply_delay: "" # how long to wait before actually apply WAL records on a standby leader (optional)
# Permanent replication slots.
# These slots will be preserved during switchover/failover.
# https://patroni.readthedocs.io/en/latest/dynamic_configuration.html
patroni_slots: []
# - slot: "logical_replication_slot" # the name of the permanent replication slot.
# type: "logical" # the type of slot. Could be 'physical' or 'logical' (if the slot is logical, you have to define 'database' and 'plugin').
# plugin: "pgoutput" # the plugin name for the logical slot.
# database: "postgres" # the database name where logical slots should be created.
# - slot: "test_logical_replication_slot"
# type: "logical"
# plugin: "pgoutput"
# database: "test"
patroni_log_destination: stderr # or 'logfile'
# if patroni_log_destination: logfile
patroni_log_dir: /var/log/patroni
patroni_log_level: info
patroni_log_traceback_level: error
patroni_log_format: "%(asctime)s %(levelname)s: %(message)s"
patroni_log_dateformat: ""
patroni_log_max_queue_size: 1000
patroni_log_file_num: 4
patroni_log_file_size: 25000000 # bytes
patroni_log_loggers_patroni_postmaster: warning
patroni_log_loggers_urllib3: warning # or 'debug'
patroni_watchdog_mode: automatic # or 'off', 'required'
patroni_watchdog_device: /dev/watchdog
patroni_postgresql_use_pg_rewind: true # or 'false'
# try to use pg_rewind on the former leader when it joins cluster as a replica.
patroni_remove_data_directory_on_rewind_failure: false # or 'true' (if use_pg_rewind: 'true')
# avoid removing the data directory on an unsuccessful rewind
# if 'true', Patroni will remove the PostgreSQL data directory and recreate the replica.
patroni_remove_data_directory_on_diverged_timelines: false # or 'true'
# if 'true', Patroni will remove the PostgreSQL data directory and recreate the replica
# if it notices that timelines are diverging and the former master can not start streaming from the new master.
# https://patroni.readthedocs.io/en/latest/replica_bootstrap.html#bootstrap
patroni_cluster_bootstrap_method: "initdb" # or "wal-g", "pgbackrest", "pg_probackup"
# https://patroni.readthedocs.io/en/latest/replica_bootstrap.html#building-replicas
patroni_create_replica_methods:
# - pgbackrest
# - wal_g
# - pg_probackup
- basebackup
pgbackrest:
- { option: "command", value: "/usr/bin/pgbackrest --stanza={{ pgbackrest_stanza }} --delta restore" }
- { option: "keep_data", value: "True" }
- { option: "no_params", value: "True" }
wal_g:
- { option: "command", value: "{{ wal_g_path }} backup-fetch {{ postgresql_data_dir }} LATEST" }
- { option: "no_params", value: "True" }
basebackup:
- { option: "max-rate", value: "1000M" }
- { option: "checkpoint", value: "fast" }
# - { option: "waldir", value: "{{ postgresql_wal_dir }}" }
pg_probackup:
- { option: "command", value: "{{ pg_probackup_restore_command }}" }
- { option: "no_params", value: "true" }
# "restore_command" written to recovery.conf when configuring follower (create replica)
postgresql_restore_command: ""
# postgresql_restore_command: "{{ wal_g_path }} wal-fetch %f %p" # restore WAL-s using WAL-G
# postgresql_restore_command: "pgbackrest --stanza={{ pgbackrest_stanza }} archive-get %f %p" # restore WAL-s using pgbackrest
# postgresql_restore_command: "pg_probackup-{{ pg_probackup_version }} archive-get -B
# {{ pg_probackup_dir }} --instance {{ pg_probackup_instance }} --wal-file-path=%p
# --wal-file-name=%f" # restore WAL-s using pg_probackup
# pg_probackup
pg_probackup_install: false # or 'true'
pg_probackup_install_from_postgrespro_repo: true # or 'false'
pg_probackup_version: "{{ postgresql_version }}"
pg_probackup_instance: "pg_probackup_instance_name"
pg_probackup_dir: "/mnt/backup_dir"
pg_probackup_threads: "4"
pg_probackup_add_keys: "--recovery-target=latest --skip-external-dirs --no-validate"
# ⚠️ Ensure there is a space at the beginning of each part to prevent commands from concatenating.
pg_probackup_command_parts:
- "pg_probackup-{{ pg_probackup_version }}"
- " restore -B {{ pg_probackup_dir }}"
- " --instance {{ pg_probackup_instance }}"
- " -j {{ pg_probackup_threads }}"
- " {{ pg_probackup_add_keys }}"
pg_probackup_restore_command: "{{ pg_probackup_command_parts | join('') }}"
pg_probackup_patroni_cluster_bootstrap_command: "{{ pg_probackup_command_parts | join('') }}"
# WAL-G
wal_g_install: false # or 'true'
wal_g_version: "3.0.3"
wal_g_path: "/usr/local/bin/wal-g --config {{ postgresql_home_dir }}/.walg.json"
wal_g_json: # config https://github.com/wal-g/wal-g#configuration
- { option: "AWS_ACCESS_KEY_ID", value: "{{ AWS_ACCESS_KEY_ID | default('') }}" } # define values or pass via --extra-vars
- { option: "AWS_SECRET_ACCESS_KEY", value: "{{ AWS_SECRET_ACCESS_KEY | default('') }}" } # define values or pass via --extra-vars
- { option: "WALG_S3_PREFIX", value: "{{ WALG_S3_PREFIX | default('s3://' + patroni_cluster_name) }}" } # define values or pass via --extra-vars
- { option: "WALG_COMPRESSION_METHOD", value: "{{ WALG_COMPRESSION_METHOD | default('brotli') }}" } # or "lz4", "lzma", "zstd"
- { option: "WALG_DELTA_MAX_STEPS", value: "{{ WALG_DELTA_MAX_STEPS | default('6') }}" } # determines how many delta backups can be between full backups
- { option: "PGDATA", value: "{{ postgresql_data_dir }}" }
- { option: "PGHOST", value: "{{ postgresql_unix_socket_dir }}" }
- { option: "PGPORT", value: "{{ postgresql_port }}" }
- { option: "PGUSER", value: "{{ patroni_superuser_username }}" }
# - { option: "AWS_S3_FORCE_PATH_STYLE", value: "true" } # to use Minio.io S3-compatible storage
# - { option: "AWS_ENDPOINT", value: "http://minio:9000" } # to use Minio.io S3-compatible storage
# - { option: "", value: "" }
wal_g_archive_command: "{{ wal_g_path }} wal-push %p"
wal_g_patroni_cluster_bootstrap_command: "{{ wal_g_path }} backup-fetch {{ postgresql_data_dir }} LATEST"
# Define job_parts outside of wal_g_cron_jobs
# ⚠️ Ensure there is a space at the beginning of each part to prevent commands from concatenating.
wal_g_backup_command:
- "curl -I -s http://{{ inventory_hostname }}:{{ patroni_restapi_port }} | grep 200"
- " && {{ wal_g_path }} backup-push {{ postgresql_data_dir }} > {{ postgresql_log_dir }}/walg_backup.log 2>&1"
wal_g_delete_command:
- "curl -I -s http://{{ inventory_hostname }}:{{ patroni_restapi_port }} | grep 200"
- " && {{ wal_g_path }} delete retain FULL 4 --confirm > {{ postgresql_log_dir }}/walg_delete.log 2>&1"
wal_g_cron_jobs:
- name: "WAL-G: Create daily backup"
user: "postgres"
file: /etc/cron.d/walg
minute: "00"
hour: "{{ WALG_BACKUP_HOUR | default('3') }}"
day: "*"
month: "*"
weekday: "*"
job: "{{ wal_g_backup_command | join('') }}"
- name: "WAL-G: Delete old backups"
user: "postgres"
file: /etc/cron.d/walg
minute: "30"
hour: "6"
day: "*"
month: "*"
weekday: "*"
job: "{{ wal_g_delete_command | join('') }}"
# pgBackRest
pgbackrest_install: false # or 'true' to install and configure backups using pgBackRest
pgbackrest_install_from_pgdg_repo: true # or 'false'
pgbackrest_stanza: "{{ patroni_cluster_name }}" # specify your --stanza
pgbackrest_repo_type: "posix" # or "s3", "gcs", "azure"
pgbackrest_repo_host: "" # dedicated repository host (optional)
pgbackrest_repo_user: "postgres" # if "repo_host" is set (optional)
pgbackrest_conf_file: "/etc/pgbackrest/pgbackrest.conf"
# config https://pgbackrest.org/configuration.html
pgbackrest_conf:
global: # [global] section
- { option: "log-level-file", value: "detail" }
- { option: "log-path", value: "/var/log/pgbackrest" }
- { option: "repo1-type", value: "{{ pgbackrest_repo_type | lower }}" }
# - { option: "repo1-host", value: "{{ pgbackrest_repo_host }}" }
# - { option: "repo1-host-user", value: "{{ pgbackrest_repo_user }}" }
- { option: "repo1-path", value: "/var/lib/pgbackrest" }
- { option: "repo1-retention-full", value: "4" }
- { option: "repo1-retention-archive", value: "4" }
- { option: "repo1-bundle", value: "y" }
- { option: "repo1-block", value: "y" }
- { option: "start-fast", value: "y" }
- { option: "stop-auto", value: "y" }
- { option: "link-all", value: "y" }
- { option: "resume", value: "n" }
- { option: "spool-path", value: "/var/spool/pgbackrest" }
- { option: "archive-async", value: "y" } # Enables asynchronous WAL archiving (details: https://pgbackrest.org/user-guide.html#async-archiving)
- { option: "archive-get-queue-max", value: "1GiB" }
# - { option: "archive-push-queue-max", value: "100GiB" }
# - { option: "backup-standby", value: "y" } # When set to 'y', standby servers will be automatically added to the stanza section.
# - { option: "", value: "" }
stanza: # [stanza_name] section
- { option: "process-max", value: "4" }
- { option: "log-level-console", value: "info" }
- { option: "recovery-option", value: "recovery_target_action=promote" }
- { option: "pg1-socket-path", value: "{{ postgresql_unix_socket_dir }}" }
- { option: "pg1-path", value: "{{ postgresql_data_dir }}" }
# - { option: "", value: "" }
# (optional) dedicated backup server config (if "repo_host" is set)
pgbackrest_server_conf:
global:
- { option: "log-level-file", value: "detail" }
- { option: "log-level-console", value: "info" }
- { option: "log-path", value: "/var/log/pgbackrest" }
- { option: "repo1-type", value: "{{ pgbackrest_repo_type | lower }}" }
- { option: "repo1-path", value: "/var/lib/pgbackrest" }
- { option: "repo1-retention-full", value: "4" }
- { option: "repo1-retention-archive", value: "4" }
- { option: "repo1-bundle", value: "y" }
- { option: "repo1-block", value: "y" }
- { option: "archive-check", value: "y" }
- { option: "archive-copy", value: "n" }
- { option: "backup-standby", value: "y" }
- { option: "start-fast", value: "y" }
- { option: "stop-auto", value: "y" }
- { option: "link-all", value: "y" }
- { option: "resume", value: "n" }
# - { option: "", value: "" }
# the stanza section will be generated automatically
pgbackrest_archive_command: "pgbackrest --stanza={{ pgbackrest_stanza }} archive-push %p"
pgbackrest_patroni_cluster_restore_command:
'/usr/bin/pgbackrest --stanza={{ pgbackrest_stanza }} --delta restore' # restore from latest backup
# '/usr/bin/pgbackrest --stanza={{ pgbackrest_stanza }} --type=time "--target=2020-06-01 11:00:00+03" --delta restore' # Point-in-Time Recovery (example)
# By default, the cron jobs is created on the database server.
# If 'repo_host' is defined, the cron jobs will be created on the pgbackrest server.
pgbackrest_cron_jobs:
- name: "pgBackRest: Full Backup"
file: "/etc/cron.d/pgbackrest-{{ patroni_cluster_name }}"
user: "postgres"
minute: "00"
hour: "{{ PGBACKREST_BACKUP_HOUR | default('3') }}"
day: "*"
month: "*"
weekday: "0"
job: "pgbackrest --stanza={{ pgbackrest_stanza }} --type=full backup"
# job: "if [ $(psql -tAXc 'select pg_is_in_recovery()') = 'f' ]; then pgbackrest --stanza={{ pgbackrest_stanza }} --type=full backup; fi"
- name: "pgBackRest: Diff Backup"
file: "/etc/cron.d/pgbackrest-{{ patroni_cluster_name }}"
user: "postgres"
minute: "00"
hour: "3"
day: "*"
month: "*"
weekday: "1-6"
job: "pgbackrest --stanza={{ pgbackrest_stanza }} --type=diff backup"
# job: "if [ $(psql -tAXc 'select pg_is_in_recovery()') = 'f' ]; then pgbackrest --stanza={{ pgbackrest_stanza }} --type=diff backup; fi"
# PITR mode (if patroni_cluster_bootstrap_method: "pgbackrest" or "wal-g"):
# 1) The database cluster directory will be cleaned (for "wal-g") or overwritten (for "pgbackrest" --delta restore).
# 2) And also the patroni cluster "{{ patroni_cluster_name }}" will be removed from the DCS (if exist) before recovery.
disable_archive_command: true # or 'false' to not disable archive_command after restore
keep_patroni_dynamic_json: true # or 'false' to remove patroni.dynamic.json after restore (if exists)
# Netdata - https://github.com/netdata/netdata
netdata_install: false # or 'true' for install Netdata on postgresql cluster nodes (with kickstart.sh)
netdata_install_options: "--stable-channel --disable-telemetry --dont-wait"
netdata_conf:
web_bind_to: "*"
# https://learn.netdata.cloud/docs/store/change-metrics-storage
memory_mode: "dbengine" # The long-term metrics storage with efficient RAM and disk usage.
page_cache_size: 64 # Determines the amount of RAM in MiB that is dedicated to caching Netdata metric values.
dbengine_disk_space: 1024 # Determines the amount of disk space in MiB that is dedicated to storing Netdata metric values.
...
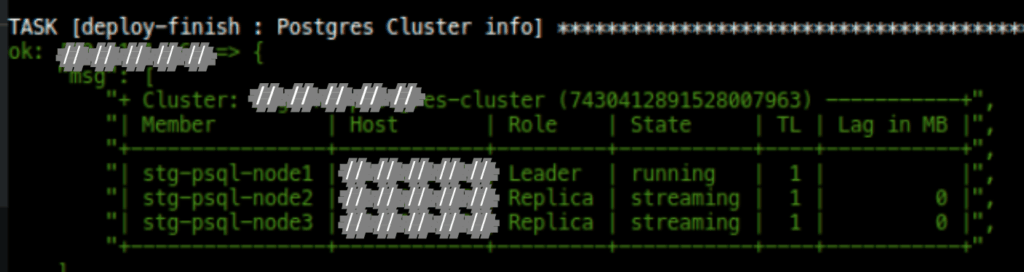
If your process was complete, then you will find message like this: Mean your cluster was ready.
Congrats!
![]()